As the Big Data landscape has evolved over the last decade, we have seen a gradual but a definitive shift in the design of the modern analytics platform from Hadoop based architecture to Apache Spark and/or Cloud-based architecture. There are many reasons for this evolution including the speed, scalability, and ease of implementation offered by the new architecture. One of the other major reasons for this change is also the storage used by the modern big data platform.
File system storage (HDFS) vs. Object storage
Traditionally, big data frameworks have been using Hadoop based architecture. At its core, Hadoop uses a file-based storage system called HDFS whereas newer analytics platforms are now being built on object-based storage systems. Examples of object-based storage systems are – Amazon S3, Microsoft Blob Storage and Google Cloud Storage just to name a few.
Some of the big reasons why object storage-based architecture is preferred over an HDFS (file system) based architecture are –
Independent Scaling
The storage in Hadoop based applications with HDFS is tied with the compute capacity. This means in order to scale storage you need to add more compute capacity even if you don’t need it. Similarly, when you need more compute capacity, you will need storage capacity as well. On the other hand, with object storage the Hadoop data lives outside the Hadoop environment (such as in the cloud) the storage layer can be scaled independently of the computing requirements.
Data Integration
Big data comes in all forms, shapes, and sizes and it’s easier and faster to store this data in object storage systems even when you are not sure how will that data be used or analyzed. Typically, object stores provide simple APIs (REST-based) or programming language interfaces to retrieve the content. This way it can be easily processed and integrated into other applications or line of business data. On the other hand, storing that data in HDFS will require additional overhead to retrieve and integrate that data with external systems.
Cost
Cloud-based object store such as Amazon S3 and Microsoft’s Azure Blob storage provide low-cost storage solutions as compared to HDFS along with features to backup and replicate data on demand. HDFS, on the other hand, makes 3 copies of each data set and thus for large voluminous datasets that contribute to a significant cost for storage.
No Single Point of Failure
Since the architecture of HDFS is based on 1 master node and a series of dependent slave nodes, it’s important to ensure that the master node is available to keep the cluster running. This necessitates the additional measures of keeping the master node from failure. This single point of failure is not a factor in an object store since it allows any node to quickly become the master node if the slave node fails.
Azure Blob Storage
Azure Blob Storage is Microsoft’s object storage systems in the cloud just like Amazon S3 and Google Cloud Storage. It offers the capacity to store exabytes of data with massive scalability cost effectively. Thus, Azure Blob storage can be used to store and process different types of unstructured data such as images, videos, audio files, and log files. Due to its low cost in storing huge volumes of data, it’s also a good choice to store backups of data that can be used for disaster recovery and archiving.
Blob Types
Azure Blob Storage provides support for 3 different types of blobs for your storage needs
Block Blobs
Block blobs are called so because they are made up of smaller units called blocks. They are typically used as general-purpose storage to store objects such as images, documents, audio and video files. Since it’s broken down into pre-defined blocks of a specific size, you can use various tools such as AzCopy, Azure Storage Explorer and the Storage SDK libraries to efficiently and quickly upload blocks in parallel to Azure Blob Storage. On the other end, Azure will assemble them into the final block blob. A block in a block blob can be of any size with a maximum of 100 MB. The maximum number of blocks allowed in a block blob is 50,000 which add up to a total of 4.75 TB.
Append Blobs
Append blobs are also composed of blocks, but those blocks can be added to the end of the blob only. In other words, you can only append to the existing blob size and you cannot update or delete any block. Since append blobs are optimized for the add operation, they are highly effective for application such as Logging, Telemetry and Streaming purposes. These blobs can also be used in industrial applications that require regulatory compliance such as insurance, finance, and legal applications. A block in an append blob can be a maximum of 4MB with a maximum number of 50,000 blocks in the append blob for a total of 195 GB.
Page Blobs
Page blob is a collection of 512-byte pages that are optimized for random read & write operations. Since you can add or update contents by writing pages inside the blob, they are well suited to store data for Virtual Machines, Database files, and backups. You can also use the Page blobs to migrate your existing VM disks to the cloud. The maximum allowed size for a Page blob is 8 TB.
For a detailed look at the blob sizes and limits, please review this link – https://docs.microsoft.com/en-us/azure/azure-subscription-service-limits#storage-limits
Overall Architecture
Azure blobs are created, stored and managed under an Azure storage account. The storage account is a container that groups together Azure Storage services and provides a unique namespace for the contained services. Since the storage account name is used as the base for the unique Resource URI that can be used to access the underlying blob, it needs to have a unique name across all Azure storage accounts. As shown in the figure, there are various settings applicable to a storage account.
The Performance setting determines what kind of services and disk would be used for your storage account. With Standard, you can use any of the 4 storage services (Blob, Queue, Table, and File) on magnetic disks whereas, with Premium, you can only store data as a Page blob on SSD storage.
Azure offers a new, improved version of storage – called General Purpose v2 which provides many advanced capabilities including specifying tiers for your blob data. Its recommended that for your new implementations, you chose the General Purpose v2 storage.
The replication option allows you to choose the type of redundancy you would like for your data. Typically, there are 4 types of redundant storage choices available, although they may not be available in all Azure data centers.
Locally Redundant Storage: The data is replicated in your chosen data center with each replica stored in a separate fault domain.
Zone Redundant Storage: The data is replicated across 3 separate storage clusters in a single region. These clusters are located in their own Availability Zone and each such zone is autonomous with its own networking and utilities.
Geo-redundant Storage: This provides the ability to replicate your data across a second region that you chose.
Read-access Geo-redundant Storage: This provides read-only access to the data in the secondary location, addition to geo-replication across 2 regions.
The access tier determines how quickly can you access your blobs in the storage account. Hot provides faster access to the data at a higher cost than Cool.
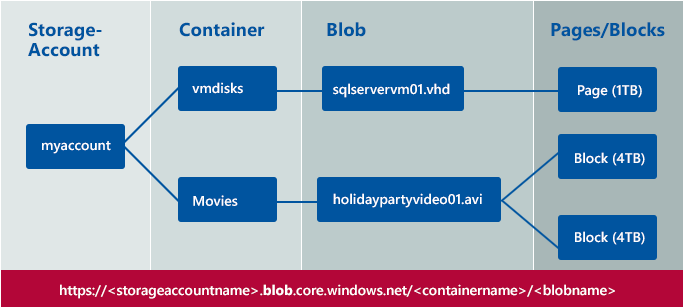
For blobs, the storage account is further made up of containers, & you can set properties such as access control and policies at the container level. It’s like a folder in a file system, but containers have their own properties & features. You cannot nest containers, but you can create folders within a container. With General Purpose v2, you can choose your storage account with a hierarchical namespace that set up a blob account with Azure Data Lake Storage Gen2 enabled.
You can have unlimited containers in a storage account and each container can have an unlimited number of blobs if they are under the storage limits defined above. The storage account name, the container name and the blob name each are part of the unique base URI used to access the individual resource. For example:
The base resource URI to access a storage account is
.blob.core.windows.net/
The base resource URI to access a blob within a container is