
Introduction:
In Part 1 of the blog series, we have learnt till how to test ADLA procedure while importing structured and semi-structured Json files into MySql Database table using Azure Data Factory & Data Analytics. In the second and last part of the series, we will learn how to create and assign permissions to service principal in a one-time setup.
Step 4: Create and assign permissions to service principal (one time setup)
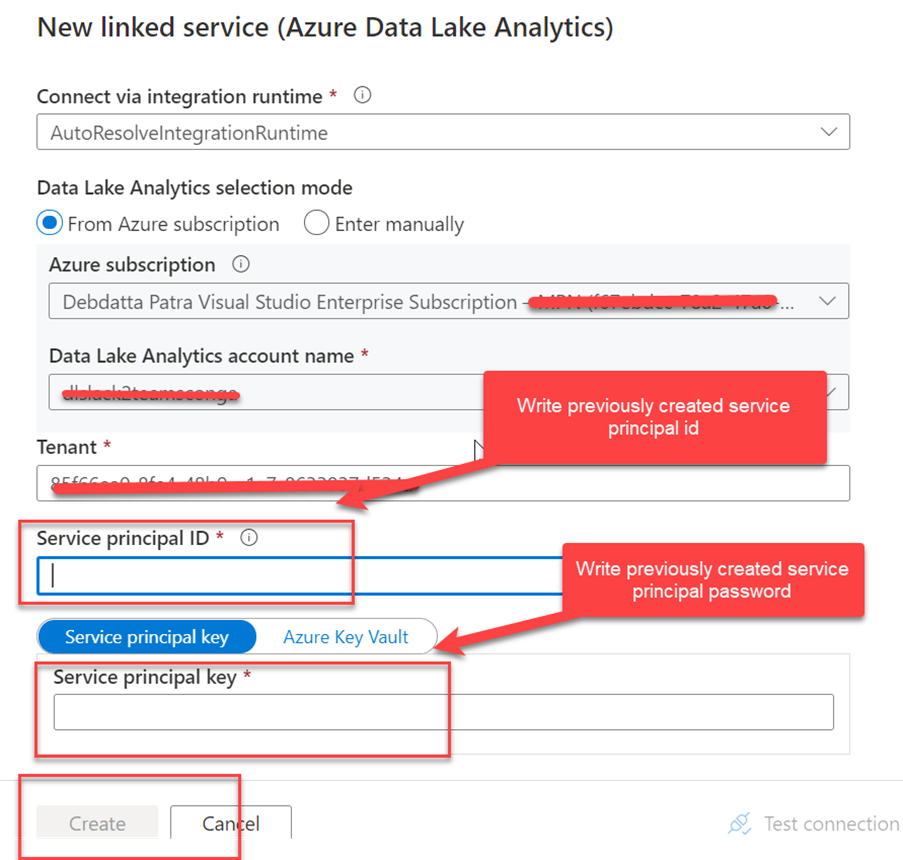
We need a link service that will communicate with the Azure Data factory and the Azure Data Analytics. AS we will call the Azure Data Analytics U-SQL store procedure form Azure Data Factory.
Please go through the link for details.
After creating the service principle, we must add read and write permission so that it can read, write ADL job trough ADF.
Step 5: Create Azure Data factory component to generate CSV file from Json file
To perform the task, we have to create two linked services, two datasets, and one pipeline those will help us in future implementation.
Linked services: One link service needed to communicate Data Factory with Azure storage account. Another linked service needed to communicate Data factory with Azure Data Analytics account, in this case we need the service principal details.
Dataset: One dataset will relate to the row Json fie and another dataset will be connected to the storage accounts for output csv file.
Pipeline: We needed one pipeline that will content one U-SQL activity, that will call previously created U-SQL store procedure.
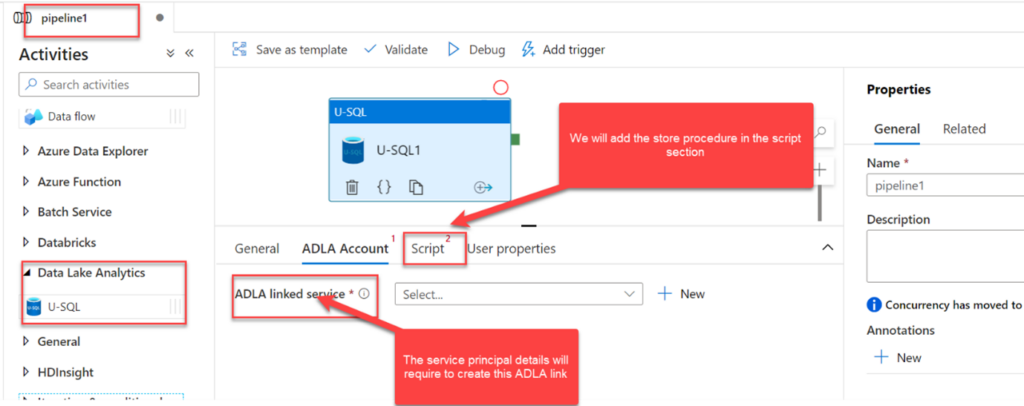
Once we click on “New” button in the ADLA Linked services option it will open a new window like below, where we have to put the service principal related information.
In the Script section we need another Linked service and dataset as below
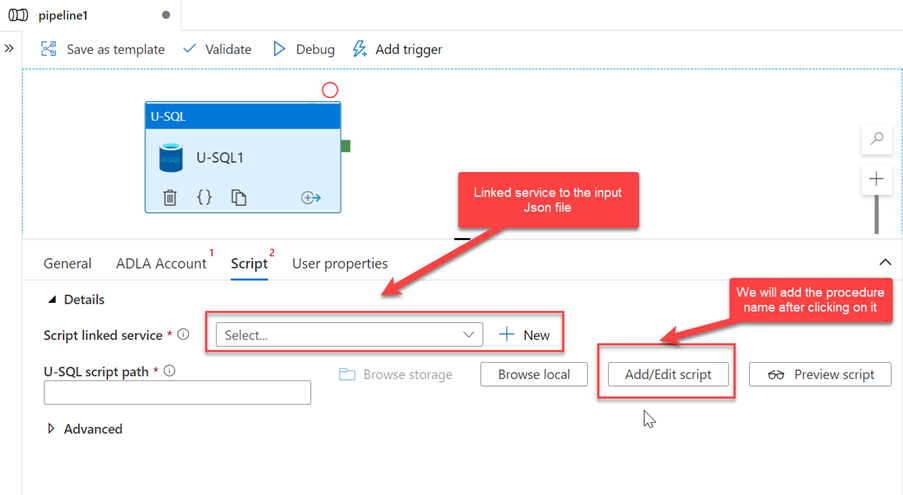
We will call the ADA procedure like below

Now we have completed all the component needed to generate the csv file form Json file. To check it, we have start debugging the pipeline as below. Once the pipeline ran properly it will create a csv file in the output folder, that provided in the U-SQL procedure.
Step 6: Data Factory pipeline to import the converted csv formatted data to MySQL table
In this case we required two Linked service, one link will communicate with csv file, and another will be with MySql database (You may use any type of relational database). We required another pipeline that will content one “Copy Activity” and two dataset We can explain it by below screen shoot.
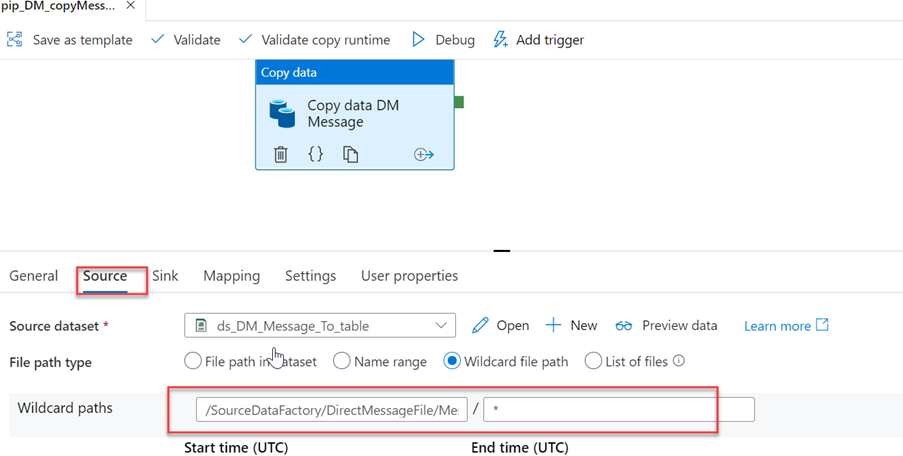
Configure source
We have to specify the source folder, that content the csv file. It will be connected with a linked service.
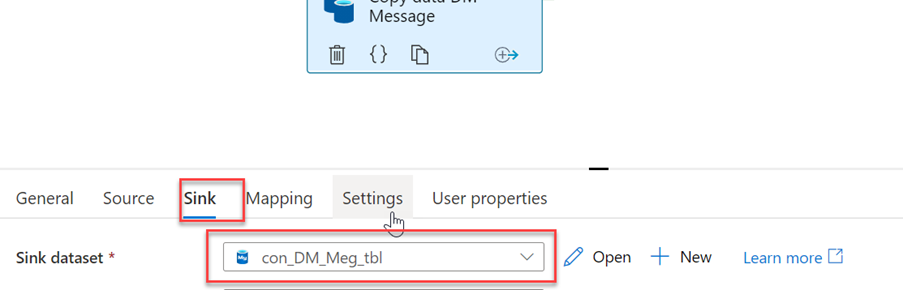
Configure Sink
In sink setting we will create a linked service that will connected to the MySql specific table where we need to insert the record from the csv file.
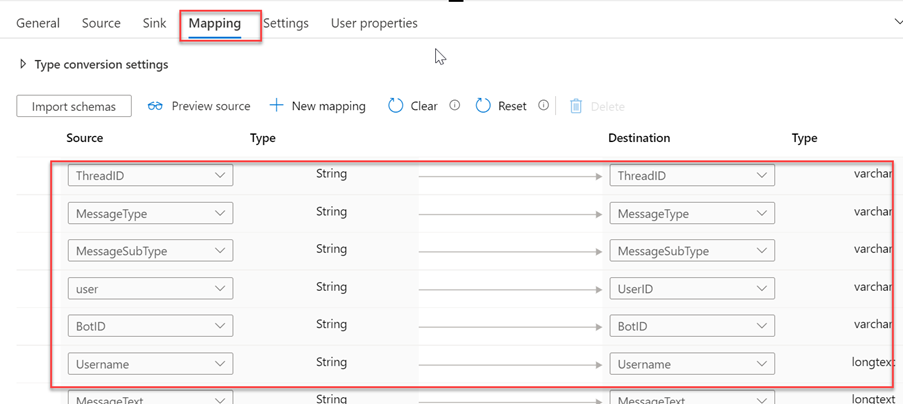
Configure mapping
In the mapping we will map the csv file column to corresponding MySql table column.
So, in this process we can store different structure Json file into a relational representation or any relational table like MySQL or MS SQL. Those record may be process to another application.


